(as of v6.5-rc5)
Introduction
The kernel's memory tiering support organizes NUMA nodes into tiers. Cold pages in the upper tier will be demoted down to the lower tier. Hot pages in the lower tier will be promoted up to the upper tier. There could be multiple tiers in total, and each neighboring tier has the above-mentioned behavior.
The kernel's memory tiering has been under development since 2019 in the vishal/tiering tree. It was finally merged into the mainline v6.1 piece by piece starting from August 2022, mainly through the following patch series:
- "NUMA balancing: optimize memory placement for memory tiering system", v13
- "memory tiering: hot page selection", v4
- "mm/demotion: Memory tiers and demotion", v15
- Other commits authored by HUANG Ying on GitHub
- mm/migrate: demote pages during reclaim
The memory tiering is built on top of Linux's NUMA balancing solution AutoNUMA. AutoNUMA's goal is to place memory close to the task accessing it or place the task close to the memory it is accessing. AutoNUMA relies on NUMA hinting page faults to collect access samples. The hotness identification algorithm is basically MRU.
AutoNUMA has lots of problems, but it gives MemTier the basic infrastructure to work on.
-
AutoNUMA's MRU cannot capture "real" hot pages. (Addressed in patch 2)
=> MemTier migrates pages based on time taken for a hint fault to occur instead of AutoNUMA's first page triggering a hint fault. This is a kind of MFU policy, but it's a bit difficult to understand. For AutoNUMA, the hint fault might have found a page that was unmapped ten rounds ago. (One round is a NUMA scanning period, roughly 60s). However, this page has very little possibility to be a hot page. A real hot page could have taken only one round to trigger a hint fault.
-
AutoNUMA does not have migration overhead control. (Addressed in patch 2)
=> MemTier migrates pages with a limited rate. This is because the fastest migration does not always mean the best application performance. One such indicator is workload responsiveness, i.e. observed latency.
-
The original watermark mechanism leaves not enough free space on the upper tier to allow promotion.
=> MemTier introduces a new watermark called promo watermark. During migration, if the target node is nearly full,
kswapdis woken to reclaim memory until thepromowatermark. Thepromowatermark is set higher than thehighwatermark so that enough space could be released to facilitate promotion. The demotion is implemented in the memory reclamation path. So, during the triggering of reclaiming towards thepromowatermark, the cold page will be demoted. The cold page is identified by Linux's LRU, i.e. active and inactive lists.
Sample collection
Samples for promotion and demotion come from different mechanisms.
-
For promotion, access samples are collected through NUMA hinting faults.
-
For demotion, samples come from the access bit located in page table entries.
They are collected during memory reclamation via page table scanning. Memory reclamation happens not often, they are mostly triggered when usable memory is low, i.e. below the
lowwatermark. But MemTier added the proactive reclamation when promotion is needed. Memory reclamation will be triggered to free enough memory, i.e. up to thepromowatermark, to facilitate promotion.
Hotness identification
Hotness identification is done differently during promotion and demotion.
-
For promotion, the strategy is MFU. MFU chooses those pages with hint fault latency smaller than the threshold, see Intro for explanation. NUMA hinting page faults require switching between user and kernel space and invalidating TLBs, which are all very expensive.
-
For demotion, the strategy is LRU.
This LRU is active and inactive lists. All
struct pages managed by them will be scanned each round to count all the access bits referencing them. Those reference bits are actually in the page table containing a page backed by the physical page managed by thisstruct page. All those page tables are found out throughrmapfollowing the structures shown here. This process requires walking the entire page table, which is also expected to be costly.
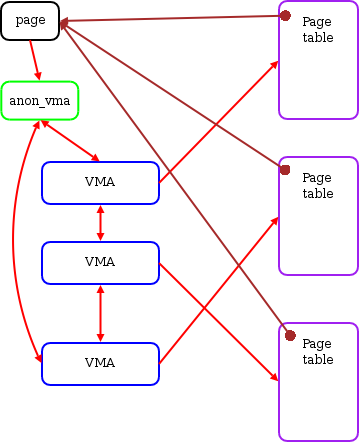{kind=link}
Page migration
Linux page migration is now rate-limited as mentioned in Intro.
Misc
By inspecting the commit log up until v6.5-rc5,
we have 12 commits involving the keyword "memory tiering".
git log --all -i --grep "memory tiering" | tee memtier.log
cat memtier.log | rg ^commit\ | cut -d\ -f2
c7cdf94e9cd7a03549e61b0f85949959191b8a10
6085bc95797caa55a68bc0f7dd73e8c33e91037f
27bc50fc90647bbf7b734c3fc306a5e61350da53
992bf77591cb7e696fcc59aa7e64d1200b673513
c959924b0dc53bf6252793f41480bc01b9792570
c6833e10008f976a173dd5abdf992e492cbc3bcf
33024536bafd9129f1d16ade0974671c648700ac
a1a3a2fc304df326ff67a1814364f640f2d5121c
c574bbe917036c8968b984c82c7b13194fe5ce98
e39bb6be9f2b39a6dbaeff484361de76021b175d
5c7b1aaf139dab5072311853bacc40fc3457d1f9
2dd57d3415f8623a5e9494c88978a202886041aa
After inspecting these commits, we found the patch series of interest linked in Intro.